An Introduction to Tiering in Application Deployment
The Background
Whilst tiering is a common enough term in the big bad world of storage, it is also appropriate to use such terminology when designing high availability solutions for application deployment. This is especially true for web based applications – and most applications are accessed by the end user through a web browser nowadays.
In somewhat crude terms, there are two main tiers:
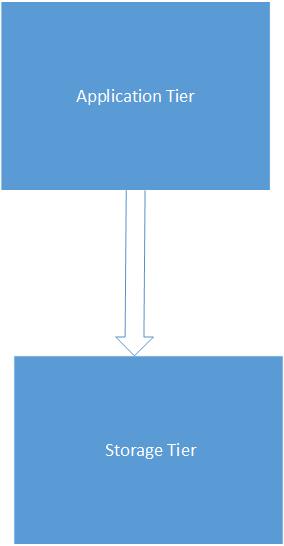
The Application Tier is the means of access to the application for the end user and can consist of one of more web servers and, in all likelihood, application delivery controllers (ADC) that provide fault tolerance, hardware load balancing and performance and security enhancements.
The Storage Tier will hold the data used by the application and will usually be a high performance database such as SQL or Oracle in a clustered configuration. Clustering allows high availability at operating system and application level. Whilst application delivery controllers can be used for load balancing database servers, this is not a particularly common scenario although they are a perfectly valid and very effective way of distributing traffic between geographically dispersed database clusters.
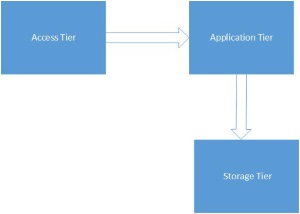
There is an additional tier relevant to this discussion that is most commonly seen in cloud deployment scenarios. This additional tier called the Access Tier is often deployed as the servers used often have no direct connection to an organisation’s internal network. All the major players – Amazon EC2/S3, Windows Azure etc. –use this kind of access control. Identity management in a cloud scenario is a complex subject that would require many words of its own so it will suffice at this stage to state that connecting users can be identified by a number of proprietary and open source technologies such as Windows Identity Foundation (WIF) for .NET applications and SAML (Security Assertion Markup Language) for the Linux/Unix applications out there. In practical terms that means that users can log in with their normal credentials to an application hosted on servers that can be in an entirely separate domain located in a data center outside the organisation’s network.
An Example
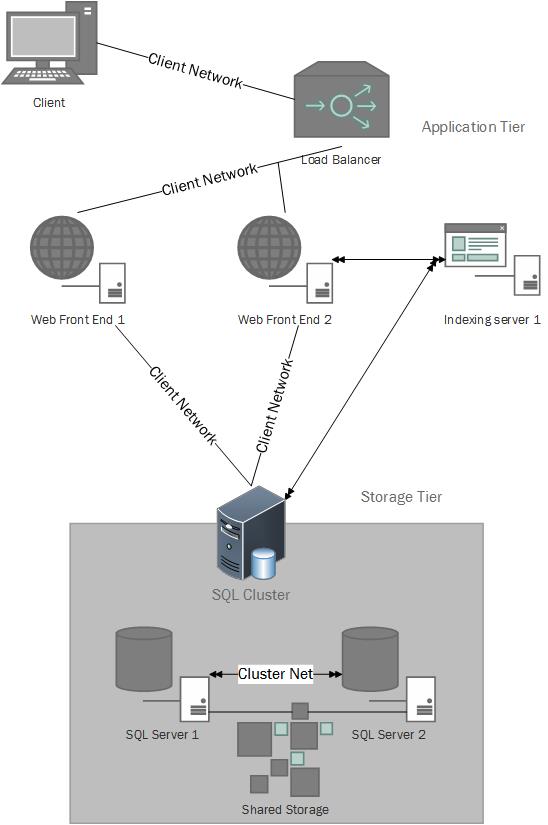
At the application tier, the client connects to a load balancer or ADC. These inbound connections are then forwarded – an ADC is a full proxy device so all inbound connections are terminated on the client side interface and a new connection is then made to one of the web front end servers. This type of deployment allows for the administrative removal of a web front end server for a reboot as the load balancer or ADC will simply redirect inbound connections to an available web front end server. The web front end servers connect to the SQL cluster on the storage tier (through a virtual IP address) to store or retrieve data. The SQL cluster may contain 2 or more nodes and the data requests or additions will be sent to one of the active nodes in the SQL cluster. Note that the SQL cluster has a separate network for communications between cluster nodes so that availability can be determined. There is no such requirement for the web front ends as they are monitored by the load balancer or ADC. A common method of monitoring involves the use of synthetic transaction where the load balancer or ADC sends an HTTP request and monitors the returned HTTP codes and data to determine if the web front end is actually able to service client connections.